
Introduction to RAG
What is Retrieval-Augmented Generation (RAG) ?
Retrieval-Augmented Generation (RAG) is an AI technique that combines the power of large language models with external knowledge sources. Instead of relying solely on the information learned during training, RAG systems can "retrieve" relevant information from databases, documents, or other sources in real-time and use that information to generate more accurate, up-to-date, and contextually relevant responses.
Think of RAG as giving an AI assistant access to a vast library. When you ask a question, the AI doesn't just rely on what it memorized during training - it can quickly search through the library, find relevant books or documents, read the pertinent sections, and then provide an answer based on that current information.
What does an RAG pipeline entail?

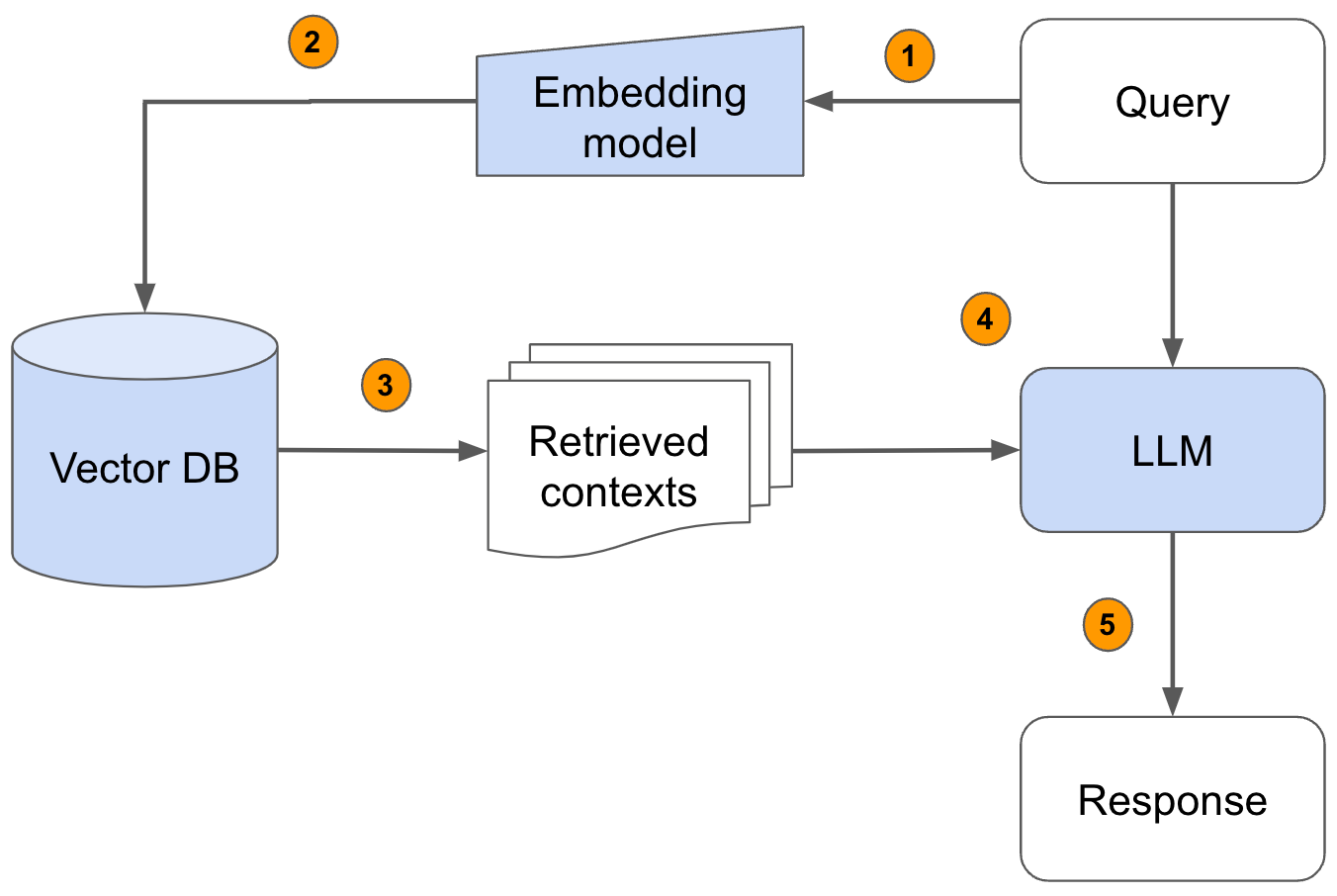{kind=link}
The RAG pipeline involves a blend of retrieval and generation. Here's a breakdown of the steps, as illustrated in the diagram:
Last updated